

大模型对语言有自己的理解!MIT论文揭示大模型“思维过程” ICML 24
2025-01-19 【 字体:大 中 小 】

大模型对现实世界,可以形成自己的理解!
MIT的一项研究发现,随着模型能力越强,它对现实的理解可能不仅是简单模仿。
比如大模型没有闻过气味,是否就意味着它不能理解气味?
研究发现,它可以自发模拟一些概念,方便理解。
这项研究意味着,大模型未来有希望更深入理解语言和世界,论文已被顶会ICML 24接收。

这篇论文的作者是MIT计算机与人工智能实验室(CSAIL)华裔博士生Charles Jin和他的导师Martin Rinard教授。
研究当中,作者让大模型只学习代码文本,结果发现模型逐渐掌握了其背后的含义。
Rinard教授表示,这项研究直接针对现代人工智能的一个核心问题——
大模型的能力仅仅是由于大规模的统计相关性,还是对它们要处理的现实问题产生了有意义的理解?
△
来源:MIT官网
同时这项研究也引发了不少讨论。
有网友表示,虽然大模型对语言的理解可能和人类不同,但这项研究至少说明了模型做的绝不仅仅是对训练数据的记忆。

让大模型学习纯代码
为了探究大模型能否产生语义层面的理解,作者构建了一个由程序代码及其对应输入输出组成的合成数据集。
这些代码程序用一种名为Karel的教学语言编写,主要用于实现机器人在2D网格世界中导航的任务。
这个网格世界由8x8的格子组成,每个格子可以包含障碍物、标记物或空地。机器人可以在格子间移动,并进行放置/拾取标记物等操作。
Karel语言包含5个原始操作——move(前进一步)、turnLeft(左转90度)、turnRight(右转90度)、pickMarker(拾取标记物)、putMarker(放置标记物),程序就是由这些原始操作的序列组成。
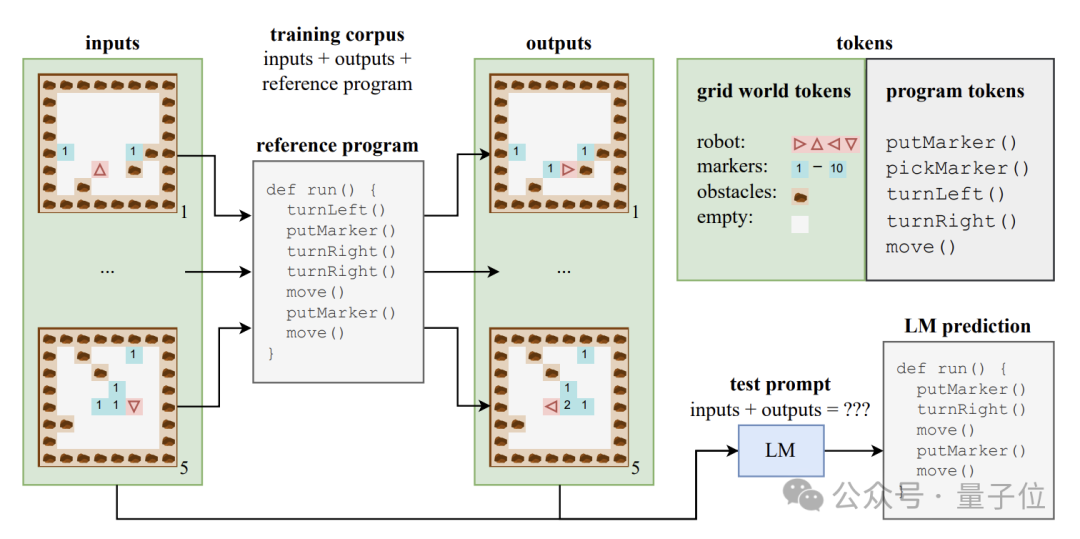
作者随机生成了一个包含50万个Karel程序的训练集,每个程序长度在6到10之间。
每个训练样本由三部分组成:5个输入状态、5个输出状态和完整的程序代码,输入输出状态以特定格式编码进字符串中。
利用这些数据,作者训练了标准Transformer架构的CodeGen模型的一个变体。
训练过程中,模型可以访问每个样本中的输入输出信息和程序前缀,但看不到程序执行的完整轨迹和中间状态。
除了训练集,作者还构建了一个包含1万个样本的测试集,用于评估模型的泛化性能。
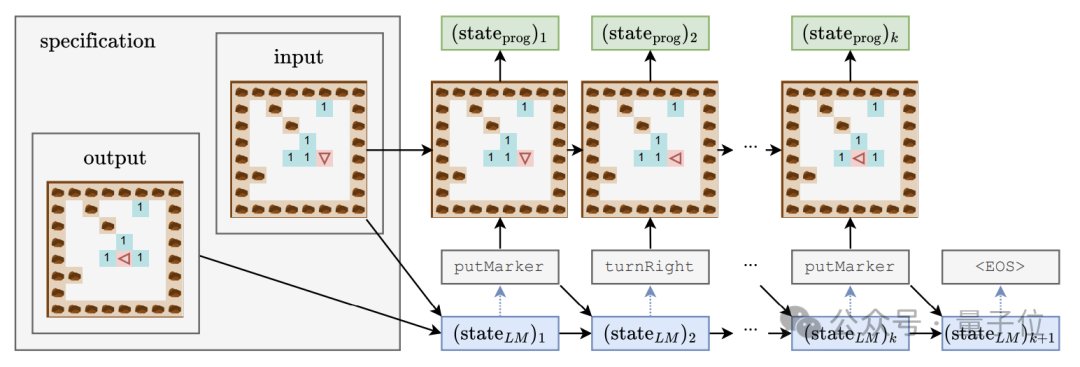
为了研究语言模型是否掌握了代码背后的语义,同时深入了解模型的“思维过程”,作者设计了一套包含线性分类器和单/双隐层MLP的探测器组合。
探测器的输入是语言模型在生成程序tokens过程中的隐藏状态,预测目标则是程序执行的中间状态,具体包括机器人的朝向(direction)、相对于初始位置的偏移量(position)以及是否正面朝向障碍物(obstacle) 这三个特征。
在生成模型的训练过程中,作者每隔4000步记录一次上述三个特征,并同时记下生成模型的隐藏状态,形成探测器的训练数据集。
大模型学习的三个阶段
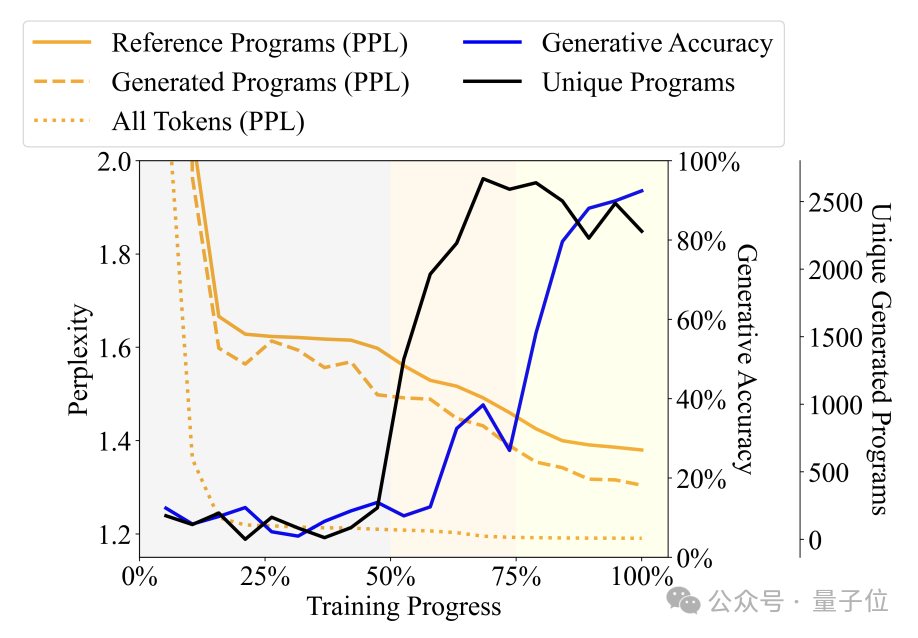
通过观察语言模型产生的程序的多样性、困惑度等指标随训练进程的变化,作者将训练过程分为了三个阶段——
Babbling(胡言乱语)阶段:输出程序重复度高,探测器准确率不稳定。
语法习得阶段:程序多样性迅速提高,生成准确率小幅提升,困惑度下降,说明语言模型习得了程序的句法结构。
语义习得阶段:程序多样性和句法结构掌握程度平稳,但生成准确率和探测器性能大幅提升,说明语言模型习得了程序的语义。
具体来说,Babbling阶段占据了整个训练过程的前50%,例如在训练到20%左右的时候,无论输入什么规范,模型都只会生成一个固定的程序——“pickMarker”重复9次。
语法习得阶段处于训练过程的50%到75%,模型在Karel程序上的困惑度显著下降,表明语言模型开始更好地适应Karel程序的统计特性,但生成程序的准确率提升幅度不大(从10%左右提升到25%左右),仍然无法准确完成任务。
语义习得阶段是最后的25%,程序的准确率出现了急剧提升,从25%左右提升到90%以上,生成的程序能够准确地完成给定的任务。
进一步实验又发现,探测器不仅可以对t时刻的同时间步进行预测,还能预测后续时间步的程序执行状态。
举例来说,假设生成模型在t时刻生成了token“move”,并将在t+1时刻生成“turnLeft”。
与此同时,t时刻的程序状态是机器人面向北方,位于坐标(0,0),而t+1时刻机器人将是机器人将面向西方,位置不变。
如果探测器能够从语言模型在t时刻的隐藏状态中,成功预测到t+1时刻机器人会面向西方,就说明在生成”turnLeft”之前,隐藏状态就已经包含了这一操作带来的状态变化信息。
这一现象说明,模型并非只对已生成的程序部分有语义理解,而是在生成每一步时,就已经对接下来要生成的内容有所预期和规划,显现出了初步的面向未来的推理能力。
但这一发现又给这项研究带来了新的问题——
实验中观察到的准确度提升,到底真的是生成模型进步了,还是探测器自己推论的结果呢?
为了解决这个疑惑,作者补充了语义探测干预实验。
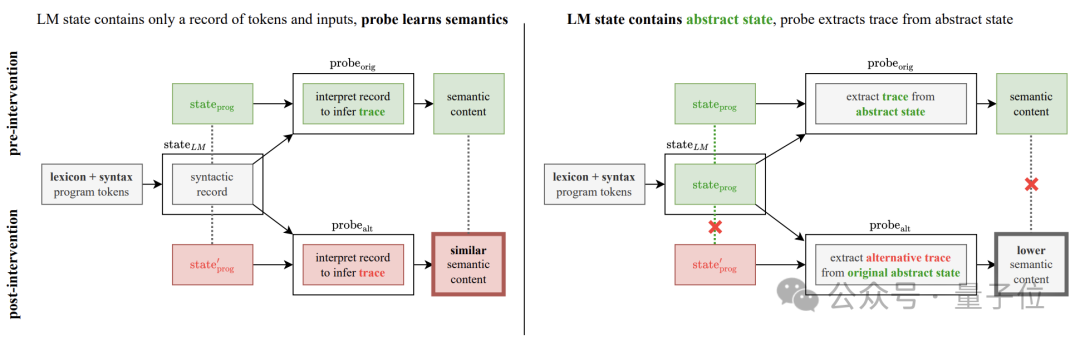
实验的基本思路是改变程序操作的语义解释规则,具体又分为“flip”和“adversarial”两种方式。
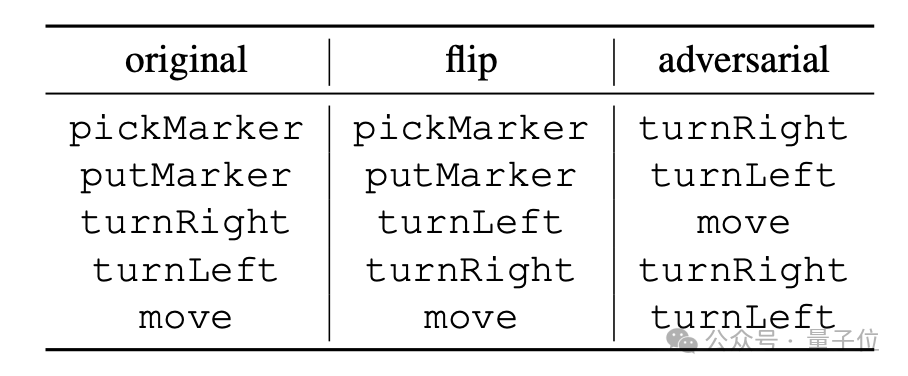
“flip”是强行反转指令含义,如将“turnRight”强行解释为“左转”不过能进行这种反转的也只有“turnLeft”和“turnRight”;
“adversarial”则是将所有指令对应的语义随机打乱,具体方式如下方表格。
如果生成模型的隐藏状态只编码了程序的句法结构,而非语义信息,那么探测器应该仍然能够从隐藏状态中以同等的性能去提取这些被改变的语义信息。
相反,如果探测器性能显著下降,则说明探测器显示出的的性能提升的确是因为生成模型隐藏状态编码了实际语义。
实验结果显示,在两种新语义下,探测器的性能都出现了显著下降。
尤其是在“adversarial”模式下更加明显,这也与该模式下的语义与原始语义差异更大的特征相一致。
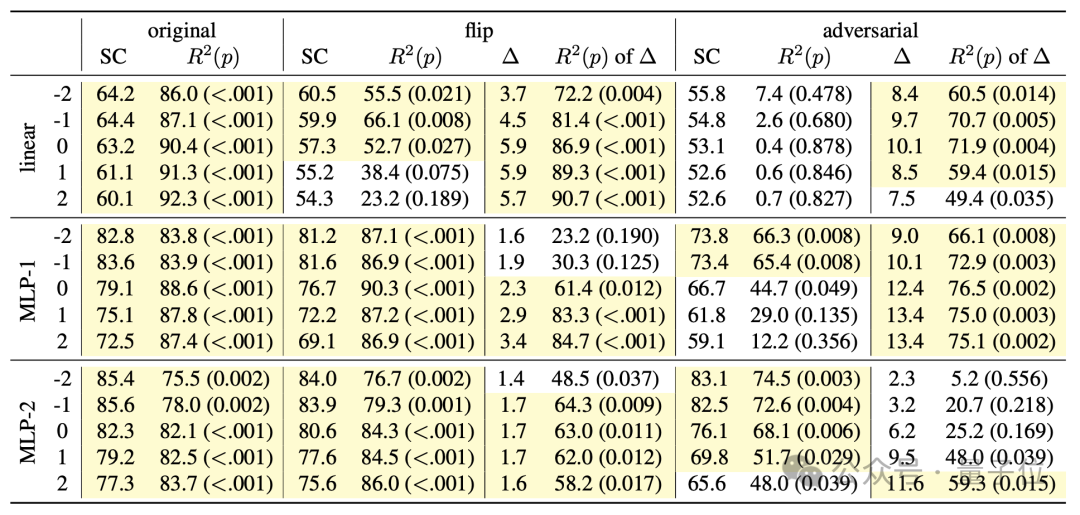
这些结果有力地排除了探测器“自己学会语义映射”的可能性,进一步证实了生成模型的确掌握了代码的含义。
— 完 —

猜你喜欢

中国财险(02328HK)1至2月原保险保费收入合计101243亿元 同比增长10%
 6977
6977 余承东回母校致辞:县理科第一名、华为留着不让走
1147 中国邮政储蓄银行和建设银行已加入鸿蒙生态系统
3113 股指配资开户:撬动财富的杠杆,亦是风险的深渊
7462 地主刘文彩的家,究竟有多豪华?77年前的建筑,至今仍奢华无比
8603 北约划下开战红线?俄军攻打乌克兰两大城市:法国军队就直接下场
6917 干货篇:什么是MACD顶背离与底背离,如何应用?这篇文章讲透了
6063 日久光电(003015)7月12日主力资金净卖出4914万元
8003 《中国红十字会成立一百二十周年》纪念邮票开机印刷
8397 一键打包价值蓝筹+成长新星,中证800ETF(159800)于今日上市交易!
192 
我是香港姑娘,做过服装设计师和空姐,现转行成民航女飞行员已5年
10月23日各投行美元、欧元、英镑、日元最新交易策略汇总

世纪华通(002602SZ):全资子公司出资19亿元与专业投资机构共同设立创投基金

ST三盛收深交所关注函 资金占用等多问题需进一步披露

与星城共谱科创华章,北京银行长沙分行全力构建“专精特新”金融支持生态链

对话三七互娱,AI究竟如何“解放”游戏?

收废品小伙上《非诚勿扰》,惨遭24盏灯全灭,报出真实身份后,女嘉宾后悔莫及

九方财富(09636HK)拟更名为九方智投控股有限公司

2024“地球一小时”活动多地联动 呼吁更多人“献出一小时”

全国人大代表王钧:完善城市排涝系统 也要关注降水较少的城市

融资炒股的风险:高收益与高风险的博弈

股指配资开户:撬动财富的杠杆,亦是风险的深渊

炒股杠杆配资网:高风险高收益的双刃剑,玩转股市需谨慎!

股票配资实盘:高风险高回报的双刃剑?

正规期货配资公司排行:避开陷阱,稳健投资
建阳市股票配资:高杠杆下的财富游戏,风险与机遇并存

股票配资可信赖?深度解析风险与机遇

大模型对语言有自己的理解!MIT论文揭示大模型“思维过程” ICML 24
【吉利星愿官图发布 搭载Flyme Auto车机系统】#吉利星愿官图

彩星集团(00635)发盈警 预计中期净亏损约115亿港元

